本篇目录:
数据挖掘总结之分类与聚类的区别
1、分类和聚类的区别:定义不同、功能不同、是否有监督、数据处理的顺序不同、算法不一样。定义不同 分类是把某个对象划分到某个具体的已经定义的类别当中,而聚类是把一些对象按照具体特征组织到若干个类别里。
2、主要区别是,性质不同、目的不同、应用不同,具体如下:性质不同 数据分类 数据分类就是把具有某种共同属性或特征的数据归并在一起,通过其类别的属性或特征来对数据进行区别。
-图1")
3、与分类技术不同,在机器学习中,聚类是一种无指导学习。也就是说,聚类是在预先不知道欲划分类的情况下,根据信息相似度原则进行信息聚类的一种方法。
4、区别:聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
5、区别是:分类是事先定义好类别 ,类别数不变 。聚类则没有事先预定的类别,类别数不确定。分类器需要由人工标注的分类训练语料训练得到,属于有指导学习范畴。
数据挖掘与预测分析术语总结
预测分析(Predictive Analytics): 从现存的数据集中提取信息以便识别模式、预测未来收益和趋势。在商业领域,预测模型及分析被用于分析当前数据和历史事实,以更好了解消费者、产品、合作伙伴,并为公司识别机遇和风险。
-图2")
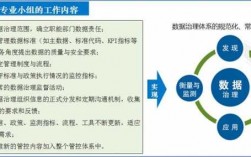
数据挖掘是数据分析的核心-广义上讲,它是指搜索数据以识别模式和趋势的整个过程。数据分析师是信息产业的坚强后盾。数据监控 预计数据分析师将定期检查数据的收集和存储,以确保其符合质量和格式标准。
数据挖掘算法:包括聚类分析、关联规则挖掘、分类、预测等,用于从数据中提取有价值的信息和知识。机器学习:利用机器学习算法对数据进行训练和学习,从而实现对数据的自动化分析和预测。
什么是数据挖掘
1、数据挖掘(英语:Datamining),又译为资料探勘、数据采矿。它是数据库知识发现(英语:Knowledge-DiscoveryinDatabases,简称:KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。
2、数据挖掘(Data Mining)是指通过大量数据集进行分类的自动化过程,以通过数据分析来识别趋势和模式,建立关系来解决业务问题。
-图3")
3、数据挖掘是从大量数据中自动发现模式、关联、趋势和隐藏信息的过程。它是将统计学、机器学习、人工智能和数据库技术相结合的交叉学科领域。数据挖掘旨在通过分析和解释数据来提取有用的知识,并用于预测、决策支持和战略规划。
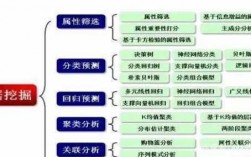
4、数据挖掘一般是指从大量的数据中自动搜索隐藏于其中的有着特殊关系性的信息的过程。主要有数据准备、规律寻找和规律表示3个步骤。数据挖掘的任务有关联分析、聚类分析、分类分析、异常分析、特异群组分析和演变分析等。
5、数据挖掘(Data mining),又译为资料探勘、数据采矿。它是数据库知识发现(Knowledge-Discovery in Databases,简称KDD)中的一个步骤。数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。
6、数据挖掘是人工智能和数据库领域研究的热点问题,所谓数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的并有潜在价值的信息的非平凡过程。
数据挖掘干货总结(四)--聚类算法
层次化聚类算法 又称树聚类算法,透过一种层次架构方式,反复将数据进行分裂或聚合。
聚类是指数据库中的数据可以划分为一系列有意义的子集,即类。在同一类别中,个体之间的距离较小,而不同类别上的个体之间的距离偏大。聚类分析通常称为“无监督学习”。
基于密度的聚类算法是一种根据对象周围的密度进行聚类的方法,它能够发现任意形状的簇,并且对噪声数据有很好的鲁棒性。 基于密度的聚类算法的定义与原理 基于密度的聚类算法是数据挖掘和机器学习领域中的一种重要技术。
数据挖掘包括什么?
1、数据挖掘涉及的科学领域和技术很多,如统计技术。统计技术对数据集进行挖掘的主要思想是:统计的方法对给定的数据集合假设了一个分布或者概率模型(例如一个正态分布)然后根据模型采用相应的方法来进行挖掘。
2、数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多方法来实现上述目标。
3、数据挖掘技术主要有决策树 、神经网络 、回归 、关联规则 、聚类 、贝叶斯分类6中。决策树技术。决策树是一种非常成熟的、普遍采用的数据挖掘技术。
4、数据挖掘一般是指从大量的数据中通过算法搜索隐藏于其中信息的过程。数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统和模式识别等诸多方法来实现上述目标。
大数据挖掘需要学习哪些技术大数据的工作
Linux操作系统、Linux常用命令、Linux常用软件安装、Linux网络、 防火墙、Shell编程等。Java 开发,掌握多线程、掌握并发包下的队列、掌握JVM技术、掌握反射和动态代理、了解JMS。
数据准备:开始收集数据,并对数据进行清洗、数据集成等操作,完成数据挖掘前的准备工作。模型建立:选择和应用各种数据挖掘模型,并进行优化,以便得到更好的分类结果。
数据分析学习偏向产品和运营,更加注重业务比如数据分析/数据运营/商业分析,主要工作包括日常业务的异常监控、客户和市场研究、参与产品开发、建立数据模型提升运营效率等。
数据挖掘算法:包括聚类分析、关联规则挖掘、分类、预测等,用于从数据中提取有价值的信息和知识。机器学习:利用机器学习算法对数据进行训练和学习,从而实现对数据的自动化分析和预测。
到此,以上就是小编对于数据挖掘的过程包括哪些步骤?每一步具体包括哪些内容的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏