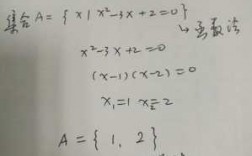本篇目录:
- 1、Hadoop,MapReduce,YARN和Spark的区别与联系
- 2、搭建spark伪分散式需要先搭建hadoop吗
- 3、简述spark的部署方式
- 4、Spark源码分析之SparkSubmit的流程
- 5、spark功能的主要入口点
- 6、spark中的rdd如何进行血统追踪
Hadoop,MapReduce,YARN和Spark的区别与联系
首先,一个job具体启动多少个map,是由你配置的inputformat来决定的。inputformat在分配任务之前会对输入进行切片。最终启动的map数目,就是切片的结果数目。
MapReduce和Spark的主要区别在于,MapReduce是批处理框架,而Spark是一个更通用的计算框架,支持批处理、流处理、图处理和机器学习等多种计算模式。背景与基础概念 首先,了解MapReduce和Spark的背景与基础概念是重要的。
-图1")
计算不同:spark和hadoop在分布式计算的具体实现上,又有区别;hadoop中的mapreduce运算框架,一个运算job,进行一次map-reduce的过程;而spark的一个job中,可以将多个map-reduce过程级联进行。
spark和hadoop的区别就是原理以及数据的存储和处理等。Hadoop一个作业称为一个Job,Job里面分为Map Task和Reduce Task阶段,每个Task都在自己的进程中运行,当Task结束时,进程也会随之结束。
MapReduce和Spark的主要区别在于数据处理方式和速度。Spark使用内存计算,而MapReduce使用硬盘计算,因此Spark在处理大数据时通常更快。 数据处理方式 MapReduce和Spark都是大数据处理技术,但它们的处理方式存在显著的差异。
搭建spark伪分散式需要先搭建hadoop吗
如果以完全分布式模式安装Spark,由于我们需要使用HDFS来持久化数据,一般需要先安装Hadoop。
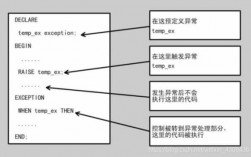
-图2")
一般都是要先装hadoop的,如果你只是玩Spark On Standalon的话,就不需要,如果你想玩Spark On Yarn或者是需要去hdfs取数据的话,就应该先装hadoop。
目的:首先需要明确一点,hadoophe spark 这二者都是大数据框架,即便如此二者各自存在的目的是不同的。Hadoop是一个分布式的数据基础设施,它是将庞大的数据集分派到由若干台计算机组成的集群中的多个节点进行存储。
不一定,如果你不用Hadoop的HDFS和YARN,完全可以在学习Spark的时候从本地载入数据,部署用standlone模式。Spark替代的是Hadoop中的MapReduce编程范式,不包括存储和资源管理模块。
Spark的安装分为几种模式,其中一种是本地运行模式,只需要在单节点上解压即可运行,这种模式不需要依赖Hadoop 环境。
-图3")
简述spark的部署方式
1、(6)配置Spark 修改和配置相关文件与Linux的配置一致,读者可以参照上文Linux中的配置方式,这里不再赘述。(7)运行Spark 1)Spark的启动与关闭 ①在Spark根目录启动Spark。./sbin/start-all.sh ②关闭Spark。
2、安装环境简介 硬件环境:两台四核cpu、4G内存、500G硬盘的虚拟机。软件环境:64位Ubuntu104 LTS;主机名分别为sparkspark2,IP地址分别为1**.1*.**.***/***。JDK版本为7。
3、部署成功后访问 http://10.1:9001/ ,输入 minio , minio123 即可看到如下界面(点击右下角可以创建bucket):详细参考 这里 Docker-compose中的 spark-master , spark-worker 组成Spark集群。
4、spark的部署方式standalone和yarn有什么区别 Names :用于改变段(segment)、组(group) 和类(class)的名字,默认值为CODE, DATA, BSS。
Spark源码分析之SparkSubmit的流程
1、首先阅读一下启动脚本,看看首先加载的是哪个类,我们看一下 spark-submit 启动脚本中的具体内容。可以看到这里加载的类是org.apache.spark.deploy.SparkSubmit,并且把启动相关的参数也带过去了。
2、在使用spark-submit提交Spark任务时,可以通过命令行参数传递当天的日期或时间。如果希望传递当前日期,可以使用--date参数,并将其值设置为yesterday或tomorrow,表示昨天或明天的日期。
3、首先看下Spark-Shell命令,其中它会调用main方法 在mian方法中,会调用spark-submit 并传入—class的参数(入口类)为org.apache.spark.repl.Main,设置应用程序名—name “Spark shell” 传入spark-shell接收的所有参数$@。
4、因为Driver在客户端,所以程序的运行结果可以在客户端显示,Driver以进程名为SparkSubmit的形式存在。
5、同时,因为Driver在客户端,所以程序的运行结果可以在客户端显 示,Driver以进程名为SparkSubmit的形式存在。
6、submitspark一直运行的解决方法:开始的时候,采用了debug模式,大范围打断点的方法,确定不到问题位置。采取逐步删代码的方法,找到原因。
spark功能的主要入口点
1、SparkContext是spark功能的主要入口点。SparkContext是Spark功能的主要入口,它代表了与Spark集群的连接,可以用于在集群上创建RDD、累加器、广播变量等。
2、RDD,Dataset。Spark编程抽象Dataset在Spark0之前,Spark的主要编程接口是RDD,在0之后RDD被Dataset所取代,从性能上和安全性上会更胜一筹。
3、SparkSession。SparkSQL介绍说明,sparksql的程序入口是SparkSession。SparkSQL作为ApacheSpark中的一个模块,将关系处理与SparkAPI集成在一起。它是专为涉及大规模数据集的只读联机分析处理(OLAP)而设计的。
4、在Spark SQL中SparkSession是创建DataFrame和执行SQL的入口,创建DataFrame有三种方式:通过Spark的数据源进行创建;从一个存在的RDD进行转换;还可以从Hive Table进行查询返回。
spark中的rdd如何进行血统追踪
partitioner指的是Spark的分区函数,目前最常用的有两种,HashPartitioner和RangePartitioner, 其次还有缩减分区数的分区函数CoalescedPartitioner。分区这个概念,只存在于(K,V)键值对的RDD中,非键值对的RDD中partitioner为None。
缓存是Spark构建迭代算法和快速交互式查询的关键。所以我们在开发过程中,对经常使用的RDD要进行缓存操作,以提升程序运行效率。RDD缓存的方法 RDD类提供了两种缓存方法:cache方法其实是将RDD存储在集群中Worker的内存中。
如果是从 HDFS 文件创建,默认为文件的 Block 数。
RDD是Spark的基础,是对大数据的抽象。它是一个弹性的分布式数据集,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来处理这些数据。
到此,以上就是小编对于spark作业提交方式的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏