本篇目录:
- 1、一个关于SQL的问题:用存储过程添加一条数据,但是想返回它的自增量ID
- 2、SQL自增字段,有数据删除后,如何实现自增字段的连续
- 3、mysql用存储过程怎么返回刚插入的主键自增长ID
- 4、如何在已有数据的表中添加id字段并且自增
- 5、SQLserver利用存储过程新加一行,id设为自动增长,结果运行后没有显示结果...
- 6、如何取得刚刚插入MSSQL自增长的id值
一个关于SQL的问题:用存储过程添加一条数据,但是想返回它的自增量ID
你可以再程序中,使用parameters[0].Direction = ParameterDirection.Output; 来接收SQL给你返回的值,也可以在存储过程中最后添加完那里加入select @@IDENTITY 直接查询最后一个插入的ID值。
自增id 的数值 db2 = INSERT INTO test_create_tab2(id,val)VALUES (1,id no use);DB21034E 该命令被当作 SQL 语句来处理,因为它是无效的“命令行处理器”命令。
-图1")
你的这个需求好象直接再把记录插入到表2就可以,但我估计你不是这个意思。比较笨的办法,可以定义一个数组用于记录表1的ID值,或者用个临时表来记录表一新增加的记录ID列表。
获取前面表新增的自增长字段的值,使用 scope_identity()你的第二个语句 insert into 表B (A_ID,DATA2) select scope_identity(),DATA2的值 这样就可以了。
首先需要打开SQL Server Managment管理工具,新建一个表。然后在表中插入一些样例数据。接下来在SQL Server Managment中右键单击可编程性,选择新建存储过程。
首先先创建一个存储过程,代码如图,存储过程主要的功能是为表JingYan插入新的数据。执行这几行代码,看到执行成功,数据库里现在已经有存储过程sp_JY。先看下JingYan表里目前的数组,如图,只有三行数据。
-图2")
SQL自增字段,有数据删除后,如何实现自增字段的连续
自增字段中用过了的值就不能在用了,所以你删除了记录他还会继续增长。可以设置set identity_insert on 然后就可以更新自增字段的值了,也可以插入自增值了。可以另建一个表,将其插入进去。
这个是不可以的,几乎每一个数据库引擎都是按照这样一个模式进行序号的递增的。
这不需改动数据库中的数据就可以实现。select row_number()over (order by id)as newID,id from test_table其中你可以查到一个新的列,不管删掉多少,还是连续的。这里id为主键,自增长。
自动ID列,如果删除了记录,再插入记录时,默认不会重用已经删除的id,因此是不连续的。但如果确实需要连续的ID,则删除后必须手工修改关于自动增长的值。
-图3")
mysql用存储过程怎么返回刚插入的主键自增长ID
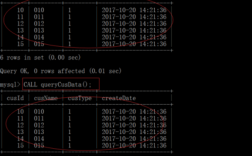
方法一是使用last_insert_id SELECT LAST_INSERT_ID();#方法二是使用max(id),但是不适用高并发环境下。
你可以在执行完insert语句后,马上执行select LAST_INSERT_ID()这个函数就可以获取到刚增记录的自增主键值了。
可能的反方案:需要找到系统表,查找到对应该表键对应的计数器,进行修改。但这样可能引起一系列的系统同步的问题。如果系统没有提供对自增加值的修改,还是不要改的好。
如何在已有数据的表中添加id字段并且自增
在创建表的时候可以设置,方法如下,用一下sql语句。create table tableName(id int identity(1,1) primary key,data varchar(50))解释:其中identity(1,1)代表自增,第一个1代表从1开始计数,第二个1代表每次增长1。
SQL语句是insert into user(name,passwd) values (name ,passwd)。新增一条数据 id 就会自动加1 INSERT INTO是sql数据库中的语句,可以用于向表格中插入新的行。
增量设置为1,点击保存按钮,需要注意的是这种方法只在创建表的时候有用,如果已经创建表成功了,再来修改会出现错误,可以先删除,再重新创建添加id字段自增。点击保存之后,添加数据的时候,id会自动递增了。
实现语句如下:alter table tableName add column id counter;注意:每张表只允许有一个自增id字段,如果已经拥有自增id字段的情况下运行上语句会报错。
如何在MYSQL插数据ID自增的方法。如下参考:在添加字段之前,第一个应该首先检查当前tb1表的结构,如下图所示。实例字段列添加到表,如下所示。再次看表结构和比较之前和之后的情况添加字段,如下图所示。
SQLserver利用存储过程新加一行,id设为自动增长,结果运行后没有显示结果...
如果语句没有差错,那只能说后者没有符合条件的结果。 如果语句出现差错,一般会有系统提示,可按提示查找原因。 另外不知是在程序中调用SQL语句、还是在企业管理器里运行的,或是在查询分析器里运行的。
先建表:createtabletest (idintnotnull,namevarchar(10))在图形界面,找到test表:右键此表名,选择“设计”。右侧出现的页面,找到要设置主键的列,ID列,然后右键,选择“设置主键”。
拿下面图举例,若设id为自动增长,选中id 设置是否标识为是,系统默认为否(否的话是不会自动增长的) 这时选择保存, 会出现上面的情况。
create table tablename (id int identity(1,1))这样设置之后,tablename数据表中的id字段就是自增列。
如何取得刚刚插入MSSQL自增长的id值
当对一张表执行insert时,如果该表有触发器程序在执行插入操作,然后,接着在另一张表中插入记录,这样返回@@identity值就是第二张表的identity值。
从学生中选择用户id 在哪里 userid=(从学生中选择最大值(userid))然后使用JSP中的语句,比如:dbconnectionDBC=newdbconnection();//DBconnection是数据库连接类。
这是在 T2 中插入的值。SCOPE_IDENTITY() 将返回在 T1 中插入的 IDENTITY 值。这是在同一个作用域内发生的最后的插入。
在连接2中向A表再插入一条记录。结果:在连接1中执行select LAST_INSERT_ID()得到的结果和连接2中执行select LAST_INSERT_ID()的结果是不同的;而在两个连接中执行select max(id)的结果是相同的。
首先,需要知道自增id的字段名字,然后就跟楼上说的一样了。
到此,以上就是小编对于存储过程trim的问题就介绍到这了,希望介绍的几点解答对大家有用,有任何问题和不懂的,欢迎各位老师在评论区讨论,给我留言。
 微信扫一扫打赏
微信扫一扫打赏